پایتون یک زبان برنامه نویسی کامپیوتری همه منظوره، سطح بالا و شی گرا است که می تواند به طور مساوی روی پلتفرم های مختلف مانند ویندوز، لینوکس، یونیکس و مکینتاش اجرا شود. یادگیری این زبان آسان است و برای توسعه برنامه ها به کد کمتری نیاز است. در حال حاضر پایتون به طور گسترده برای موارد زیر استفاده می شود: - علم داده (Data Science)، یادگیری ماشین و حوزه هوش مصنوعی - توسعه وب (سمت سرور) - توسعه نرم افزار - ریاضیات - برنامه نویسی سیستم (System Scripting)

- یک زبان تفسیر شده (Interpreted) است نیازی به کامپایل قبلی کد ندارد و دستورالعمل ها را مستقیماً اجرا می کند. - رایگان و متن باز (Open Source) بوده و برای استفاده مجدد در دسترس عموم است. می توان آن را به صورت رایگان دانلود کرد. - بسیار منعطف و با هر ماژولی قابل توسعه است. - از مفاهیم شی گرایی برای ارائه راه حل های کاربردی استفاده میکند. - ساختارهای داده ای داخلی مانند Tuple، List و Dictionary ساختارهای داده یکپارچه مفیدی هستند که توسط این زبان ارائه می شوند. - برنامه های پایتون می توانند بر روی پلتفرم های متقابل اجرا شوند بدون اینکه بر عملکرد آن تأثیر بگذارند. - خوانایی، سطح بالا، کراس پلت فرم بودن از قابلیت های دیگر این زبان است.

قبل از اینکه معنی نوع پویا را بفهمیم، باید بدانیم که منظور از نوع (Type) چیست. نوع شناسی (Typing) همانگونه که از اسمش پیداست به بررسی نوع مقادیر در زبان های برنامه نویسی اشاره دارد. در یک زبان با تایپ قوی (Strongly-Typed)، مانند پایتون ، 2+ "1" منجر به یک خطای نوع می شود زیرا این زبان ها اجازه تبدیل ضمنی نوع داده ها را نمی دهند. از طرف دیگر، یک زبان با تایپ ضعیف(Weakly-Typed) مانند جاوا اسکریپت، به سادگی "12" را در نتیجه خروجی می دهد. بررسی نوع می تواند در دو مرحله انجام شود: - Static: نوع داده ها قبل از اجرا بررسی می شوند. - Dynamic: نوع داده ها در حین اجرا بررسی می شوند. پایتون یک زبان تفسیر شده است، هر عبارت را خط به خط اجرا می کند و بنابراین بررسی نوع در حین اجرا انجام می شود. از این رو، پایتون یک زبان نوع پویا است.

یک زبان Interpreted دستورات خود را خط به خط و بدون نیاز به کامپایل شدن اجرا می کند. زبان هایی مانند پایتون، جاوا اسکریپت، R، PHP و Ruby نمونه هایی از زبان های تفسیر شده هستند.

PEP مخفف عبارت Python Enhancement Proposal است و میتوان آن را به عنوان سندی تعریف کرد که به ما در ارائه دستورالعملهایی در مورد نحوه نوشتن کد پایتون کمک میکند. اساساً مجموعه ای از قوانین است که نحوه قالب بندی کد پایتون را برای حداکثر خوانایی مشخص می کند.

لیست ها و تاپل ها هر دو نوع داده های دنباله ای(sequence data types) هستند که می توانند مجموعه ای از اشیاء را در پایتون ذخیره کنند. اشیاء ذخیره شده در هر دو دنباله می توانند انواع مختلفی داشته باشند. لیست ها با کروشه های مربع نشان داده می شوند [maryam', 6, 0.19']، در حالی که تاپل ها با پرانتز نمایش داده می شوند (ali', 5, 0.97'). اما تفاوت واقعی این دو چیست؟ تفاوت اصلی بین این دو این است که لیست ها قابل تغییر(mutable) هستند اما تاپل ها تغییر ناپذیرند(immutable ). این بدان معنی است که لیست ها را می توان در حال اجرا تغییر داد، اضافه کرد یا تکه تکه کرد، اما تاپل ها ثابت می مانند و به هیچ وجه نمی توان آنها را تغییر داد. برای تایید تفاوت می توانید مثال زیر را در Python IDLE اجرا کنید:

my_tuple = ('maryam', 6, 5, 0.97)
my_list = ['maryam', 6, 5, 0.97]
print(my_tuple[0]) # output => 'maryam'
print(my_list[0]) # output => 'maryam'
my_tuple[0] = 'ali' # modifying tuple => throws an error
my_list[0] = 'ali' # modifying list => list modified
print(my_tuple[0]) # output => 'maryam'
print(my_list[0]) # output => 'ali'حافظه پایتون توسط فضای پشته(Heap) خصوصی پایتون مدیریت می شود. تمام اشیاء و ساختارهای داده پایتون در یک پشته خصوصی قرار دارند. برنامه نویس به این پشته خصوصی دسترسی ندارد و مفسر(Interpreter) از این پشته خصوصی پایتون مراقبت می کند. تخصیص فضای پشته پایتون برای اشیاء پایتون توسط مدیر حافظه پایتون انجام می شود. هسته API به برنامه نویس امکان دسترسی به برخی از ابزارها را برای کدنویسی می دهد. پایتون همچنین دارای یک جمع کننده زباله(Garbage Collector) داخلی است که تمام حافظه استفاده نشده را بازیافت می کند و حافظه را آزاد می کند و آن را در فضای پشته در دسترس قرار می دهد.

PyChecker یک ابزار تجزیه و تحلیل استاتیک است که باگ های موجود در کد منبع پایتون را شناسایی می کند و در مورد سبک و پیچیدگی باگ هشدار می دهد. Pylint ابزار دیگری است که بررسی می کند آیا ماژول با استاندارد کدنویسی مطابقت دارد یا خیر.

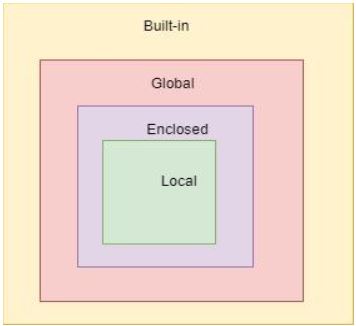
هر شی در پایتون در یک محدوده عمل می کند. scope بلوکی از کد است که یک شی در آن قابل استفاده ودسترسی است. فضاهای نام به طور منحصر به فرد تمام اشیاء داخل یک برنامه را شناسایی می کنند. با این حال، این برای فضاهای نام نیز یک محدوده تعریف شده است که می توانید از اشیاء آنها بدون هیچ پیشوندی استفاده کنید. چند نمونه از محدوده های ایجاد شده در هنگام اجرای کد در پایتون به شرح زیر است: - محدوده محلی(local scope) به اشیاء محلی قابل دسترسی در تابع فعلی اشاره دارد. - محدوده جهانی(global scope) به اشیاء قابل دسترسی در سراسر کد از زمان ایجاد آنها اشاره دارد. - محدوده سطح ماژول(module-level scope) به اشیاء سراسری ماژول فعلی، قابل دسترسی در برنامه اشاره دارد. - بیرونی ترین محدوده(outermost scope) به همه نام های داخلی(built-in) قابل فراخوانی در برنامه اشاره دارد.
چندین نوع داده داخلی در پایتون وجود دارد. اگرچه، پایتون نیازی به تعریف صریح انواع داده در طی اعلان متغیرها ندارد. اگر دانش انواع دادهها و سازگاری آنها با یکدیگر نادیده گرفته شود، احتمالاً خطاهای نوع رخ میدهد. پایتون توابع ()type و ()ininstance را برای بررسی نوع این متغیرها فراهم می کند. داده های داخلی پایتون را می توان به دسته های زیر دسته بندی کرد: 1- None Type: کلمه کلیدی None مقدار تهی را در پایتون نشان می دهد. عملیات برابری بولی را می توان با استفاده از این اشیاء NoneType انجام داد. 2- Numeric Type: سه نوع عددی(Numeric) متمایز وجود دارد - اعداد صحیح(integer)، اعداد ممیز شناور(floating-point) و اعداد مختلط(complex). بعلاوه، بولی ها زیرشاخه ای از اعداد صحیح هستند. بعلاوه، بولیین ها(boolean) زیرشاخه ای از اعداد صحیح هستند. 3- Sequence Type: طبق اسناد پایتون، سه نوع توالی اصلی(basic Sequence) وجود دارد - لیست ها(list)، تاپل ها(tuple) و محدوده(range). انواع توالی دارای عملگرهای in و not in هستند که برای پیمایش عناصرشان تعریف شده اند. این اپراتورها اولویت مشابهی با عملیات مقایسه دارند. 4- Mapping Type: یک شی نگاشت(mapping) می تواند مقادیر قابل هش را به اشیاء تصادفی در پایتون نگاشت کند. اشیاء نگاشت Mutable هستند و در حال حاضر تنها یک نوع استاندارد نگاشت وجود دارد، dictionary. 5-

تابع بخشی از برنامه یا بلوک کدی است که یک بار نوشته می شود و هر زمان که در برنامه لازم باشد می توان آن را اجرا کرد. یک تابع دارای نام، لیستی از پارامترها و بدنه معتبر است. توابع کدهای ما را کاربردی تر و ماژولارتر می کنند. پایتون توابع داخلی(Built-in) متعددی دارد و همچنین به کاربر اجازه می دهد تا توابع جدید را نیز ایجاد کند. سه نوع تابع در پایتون وجود دارد: - توابع داخلی: ()copy()، len()، count برخی از توابع داخلی هستند. - توابع تعریف شده توسط کاربر: توابعی که توسط کاربر به نام توابع تعریف شده توسط کاربر تعریف می شوند. - توابع ناشناس(Anonymous ): این توابع به توابع لامبدا نیز معروفند زیرا با کلمه کلیدی استاندارد def تعریف نمی شوند. سینتکس کلی تابع تعریف شده توسط کاربر در زیر آمده است:

def function_name(parameters list):
#--- statements---
return a_value دو مکانیزم برای پاس دادن پارامتر به توابع در پایتون وجود دارد: - با رفرنس (By Reference): بهطور پیشفرض، تمام پارامترها (آرگمونها) با رفرنس به توابع ارسال میشوند. بنابراین، اگر مقدار پارامتر را در یک تابع تغییر دهید، این تغییر در تابعی که آن را فراخوانده نیز منعکس می شود. به عنوان مثال، اگر یک متغیر به عنوان a = 10 اعلام شود، و به تابعی ارسال شود که در آن مقدار آن به a = 20 تغییر یابد. هر دو متغیر برابر میشوند. - با مقدار (By Value): ارسال با مقدار به این صورت است که هرگاه آرگومانها را به تابع میدهیم، فقط مقادیر به تابع منتقل میشوند، هیچ رفرنسی به تابع منتقل نمیشود و این کار پرامترها را تغییرناپذیر(Immutable) می کند. بنابرین دو تابع مقادیر مختلف را نگه می دارند و مقدار اصلی حتی پس از تغییر در تابع فراخوانی شده ثابت باقی می ماند.

By Reference Example:
student = {'Jim': 12, 'Anna': 14, 'Preet': 10}
def test(student):
new = {'Sam':20, 'Steve':21}
student.update(new)
print("Inside the function", student)
return
test(student)
print("Outside the function:", student)
Ouput:
Inside the function:{'Jim': 12, 'Anna': 14, 'Preet': 10,'Sam':20, 'Steve':21}
Outside the function:{'Jim': 12, 'Anna': 14, 'Preet': 10,'Sam':20, 'Steve':21}
-------------------------------------------------------------------------------------
Call By Value Example:
student = {'Jim': 12, 'Anna': 14, 'Preet': 10}
def test(student):
student = {'Sam':20, 'Steve':21}
print("Inside the function", student)
return
test(student)
print("Outside the function:", student)
Output:
Inside the function:{'Jim': 12, 'Anna': 14, 'Preet': 10,'Sam':20, 'Steve':21}
Outside the function:{'Jim': 12, 'Anna': 14, 'Preet': 10,'Sam':20, 'Steve':21}تابع zip() یک شی zip را برمیگرداند، که یک مجموعه قابل شمارش از چند تاپل(Tuple) است. در آن اولین آیتم از هر مجموعه با هم جفت میشود و سپس آیتم های دوم با هم جفت میشوند و الی آخر. اگر مجموعه های پاس شده دارای طول های متفاوتی باشند، مجموعه با کمترین طول، تعداد تاپل های مجموعه جدید را تعیین می کند.

a = ("Hadi", "Hooman", "Mohammad")
b = ("Mahsa", "Rana", "Sarah")
x = zip(a, b)
print(tuple(x))
Output:
(('Hadi','Mahsa'),('Hooman','Rana'),('Mohammad','Sara'))
عبارت pass به عنوان یک نگهدار نده (Placeholder) برای کدهای آینده استفاده می شود. وقتی دستور pass اجرا میشود، هیچ اتفاقی نمیافتد، اما وقتی کد خالی مجاز نیست، از دریافت خطا جلوگیری میکنید. کد خالی در حلقه ها، تعاریف تابع، تعاریف کلاس، یا در دستورات if مجاز نیست.

def myEmptyFunc():
# do nothing
pass
myEmptyFunc() پکیج ها و ماژول های پایتون دو مکانیزم هستند که امکان برنامه نویسی ماژولار را در پایتون فراهم می کنند. ماژولار کردن برنامه ها چندین مزیت دارد: - سادگی: کار بر روی یک ماژول به شما کمک می کند تا روی بخش نسبتاً کوچکی از مساله تمرکز کنید. این باعث می شود توسعه آسان تر و کمتر در معرض خطا باشد. - قابلیت نگهداری: ماژول ها برای اعمال مرزهای منطقی بین حوزه های مختلف مساله طراحی شده اند. اگر آنها به گونه ای نوشته شده باشند که وابستگی متقابل را کاهش دهد، احتمال کمتری وجود دارد که تغییرات در یک ماژول بر سایر بخش های برنامه تأثیر بگذارد. - قابلیت استفاده مجدد: توابع تعریف شده در یک ماژول می توانند به راحتی توسط سایر بخش های برنامه مجددا استفاده شوند. - محدوده: ماژول ها معمولاً یک فضای نام جداگانه تعریف می کنند که به جلوگیری از سردرگمی بین شناسه های سایر بخش های برنامه(مانند متغییرهای هم نام) کمک می کند. ماژول ها به طور کلی فایل های پایتون با پسوند py هستند که می توانند شامل مجموعه ای از توابع، کلاس ها یا متغیرها باشند. آنها را می توان یک بار با استفاده از دستور import وارد و مقدار دهی اولیه کرد. پکیج ها امکان ایجاد ساختار سلسله مراتبی برای فضای نام ماژول را با استفاده از نماد دات (.) فراهم می کنند. همانطور که ماژول ها از سردرگمی بین نام متغیرهای سراسری جلوگیری می کنند، به روشی مشابه، پکیج ها نیز به جلوگیری از سردرگمی بین نام ماژول ها کمک می کنند. ایجاد یک پکیج آسان است فقط ماژول ها را در یک پوشه قرار دهید و از نام پوشه به عنوان نام پکیج استفاده کنید. برای وارد کردن(Import) یک ماژول یا محتویات آن از این پکیج،به نام پکیج به عنوان پیشوند نام ماژول که با یک نقطه به هم وصل شده اند، نیاز دارید.

سوالی هست که اینجا نمیبینیش و از نظر تو مهمه؟ خودت سوالی داری که دنبال جوابشی؟ جواب بهتری واسه یکی از سوالای بالا داری؟ پس واسمون بفرست.