علم داده ترکیبی از الگوریتم ها ، ابزارها و تکنیک های یادگیری ماشین است که به شما کمک می کند الگوهای پنهان را از داده های خام داده شده بیابید.

رگرسیون لجستیک یک دسته بند باینری است که احتمال قرار گرفتن در هر دسته را بر اساس تابع سیگموید محاسبه می کند. بنابراین همواره مقداری بین 0 و 1 دارد. برای تخمین احتمال عضویت در بیش از دو دسته فرض می کند که به تعداد نتایج محتمل دسته بند باینری رگرسیون لجستیک وجود دارد.

یادگیری تحت نظارت: - از داده های شناخته شده و برچسب دار به عنوان ورودی استفاده می کند. - یادگیری تحت نظارت مکانیسم بازخورد دارد. - رایج ترین الگوریتم های یادگیری تحت نظارت درخت تصمیم ، رگرسیون لجستیک و ماشین بردار پشتیبان هستند. یادگیری بدون نظارت: - از داده های بدون برچسب به عنوان ورودی استفاده می کند. - یادگیری بدون نظارت مکانیزم بازخورد ندارد. - رایج ترین الگوریتم های یادگیری بدون نظارت عبارتند از خوشه بندی k-means ، خوشه بندی سلسله مراتبی و الگوریتم apriori.

درخت تصمیم یک الگوریتم محبوب یادگیری ماشین تحت نظارت است که از ساختار درختی برای دسته بندی یا رگرسیون استفاده می کند. در این الگوریتم نود ها(Nodes) نشان دهنده ویژگی ها(Features) و برگ ها(Leafs) نشان دهنده کلاس ها هستند. الگوریتم با این سوال کارش را آغاز می کند: کدام نود یا ویژگی باید برای توسعه انتخاب شود؟ یک تست آماری برای تعیین اینکه هر ویژگی چقدر می تواند به تنهایی نمونه ها را دسته بندی کند، انجام می شود. این تست آماری بهره اطلاعاتی(Information Gain) نامیده میشود که بر اساس آنتروپی(Entropy) محاسبه می شود.

1. کل مجموعه داده را به عنوان ورودی در نظر بگیرید 2. آنتروپی متغیر هدف و همچنین ویژگی های پیش بینی کننده را بدست آورید. 3. بهره اطلاعاتی(Information Gain) تمام ویژگی ها محاسبه کنید. 4. ویژگی با بیشترین بهره اطلاعاتی را به عنوان گره ریشه انتخاب کنید. 5. تا زمانی که گره تصمیم گیری هر شاخه نهایی نشود ، همین روش را روی هر شاخه تکرار کنید.

جنگل تصادفی یک الگوریتم یادگیری نظارت شده(Supervised Learning Algorithm) است که هم برای طبقه بندی(Classification) و هم برای رگرسیون(Regression) استفاده می شود. اما با این حال، عمدتاً برای مسائل طبقه بندی استفاده می شود. همانطور که می دانیم یک جنگل از درختان تشکیل شده است و درختان بیشتر به معنای جنگل قوی تر است. به همین ترتیب الگوریتم جنگل تصادفی درخت های تصمیم را بر روی نمونه های داده ایجاد می کند و سپسهر یک از آنها نتیجه را پیش بینی می کند و در نهایت با رای گیری بهترین راه حل را انتخاب می کند. این یک روش مجموعه ای است که بهتر از یک درخت تصمیم گیری منفرد است، زیرا با میانگین گیری نتیجه، برازش بیش از حد(Over Fitting) را کاهش می دهد.

الگوریتم های رگرسیون و طبقه بندی، الگوریتم های یادگیری نظارت شده(Supervised Learning Algorithms) هستند. هر دو الگوریتم برای پیشبینی در یادگیری ماشین و کار با مجموعه دادههای برچسبگذاری شده استفاده میشوند. اما تفاوت بین هر دو در نحوه استفاده از آنها برای مسائل مختلف یادگیری ماشین است. تفاوت اصلی الگوریتمهای رگرسیون و طبقهبندی این است که الگوریتمهای رگرسیون برای پیشبینی مقادیر پیوسته مانند قیمت، حقوق، سن و غیره و الگوریتمهای طبقهبندی برای پیشبینی/طبقهبندی مقادیر گسسته مانند مرد یا زن، درست یا نادرستT هرزنامه(Spam) یا غیر هرزنامه و غیره استفاده میشوند.

بایاس یکی از انواع خطاها است که به دلیل فرضیات اشتباه در مورد داده ها (ساده گی بیش از حد مدل) مانند فرض خطی بودن داده ها رخ می دهد درحالی که در واقعیت، داده ها از یک تابع پیچیده پیروی می کنند. از سوی دیگر، واریانس میزان تغییرات تابع هدف در تخمین خروجی در صورت استفاده از دادهای مختلف است. حساسیت بالای واریانس به تغییرات باعث می شود که گاهی نویز را نیز مدل کند بنابراین این نیز یکی از انواع خطاها است زیرا ما می خواهیم مدل خود را در برابر نویز مقاوم کنیم. معمولا وجود بایاس کوچک برای پارامترها منجر به واریانس بزرگ برای مدل خواهد شد. البته برعکس این حالت نیز وجود دارد، به این معنی که با کوچک کردن واریانس مدل، با مشکل بزرگ شدن بایاس مواجه خواهیم شد. هدف ما پیدا کردن مدلی است که بتواند بهترین موازنه را بین بایاس و واریانس ایجاد کند. نکته: الگوریتم های یادگیری ماشین خطی اغلب دارای بایاس زیاد اما واریانس کم هستند. الگوریتمهای یادگیری ماشین غیرخطی اغلب بایاس کم اما واریانس بالایی دارند.

بایاس پایین: - Decision Tree - K-Nearest Neighbor - Support Vector Machine بایاس بالا: - Linear Regression - Linear Discriminant Analysis- - Logistic Regression

واریانس بالا: - Decision Trees - k-Nearest Neighbors and - Support Vector Machines واریانس پایین: - Linear Regression - Linear Discriminant Analysis - Logistic Regression

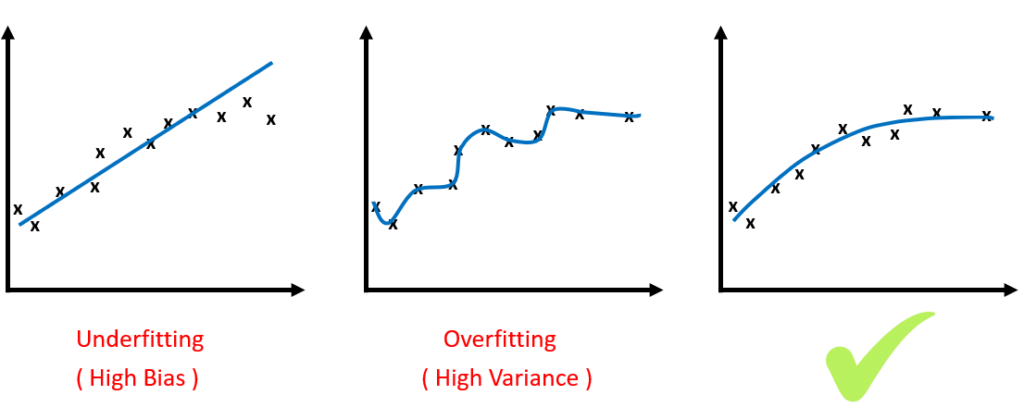
به طور کلی Overfitting عملکرد خوب در داده های آموزشی، تعمیم ضعیف به داده های دیگر است. ولی Underfitting عملکرد ضعیف در داده های آموزشی و تعمیم ضعیف به داده های دیگر است. Overfitting زمانی اتفاق میافتد که یک مدل جزئیات و نویز موجود در دادههای آموزشی را تا حدی بیاموزد که بر عملکرد مدل در دادههای جدید تأثیر منفی بگذارد. این به این معنی است که نویز یا نوسانات تصادفی در داده های آموزشی به عنوان مفاهیم توسط مدل انتخاب شده و آموخته می شود. مشکل این است که این مفاهیم برای دادههای جدید اعمال نمیشوند و بر توانایی مدلها برای تعمیم تأثیر منفی میگذارند. Overfitting در مدلهای غیرپارامتریک و غیرخطی که انعطافپذیری بیشتری در هنگام یادگیری تابع هدف دارند، بیشتر است. به این ترتیب، بسیاری از الگوریتمهای یادگیری ماشین غیرپارامتریک نیز به دنبال تکنیکهایی برای محدود کردن جزئیاتی هستند که مدل یاد میگیرد. به عنوان مثال، درخت تصمیم یک الگوریتم یادگیری ماشین غیرپارامتریک است که بسیار انعطافپذیر است و در معرض Overfitting قرار میگیرد. این مشکل را می توان با هرس کردن یک درخت پس از یادگیری به منظور حذف بخشی از جزئیاتی که برداشت کرده است، برطرف کرد. Underfitting به مدلی اطلاق می شود که نه می تواند داده های آموزشی را مدل کند و نه می تواند به داده های جدید تعمیم دهد. مسلما یک مدل یادگیری ماشین نامناسب عملکرد ضعیفی در داده های آموزشی خواهد داشت که منجر به Underfitting خواهد شد، ولی متاسفانه معیار ارزیابی مناسبی جهت تشخیص Underfitting وجود ندارد. راه حل این است الگوریتم های یادگیری ماشینی جایگزین را امتحان کنید و بهترین را از میان آن ها انتخاب کنید.

Overfitting زمانی اتفاق می افتد که یک مدل آماری یا الگوریتم یادگیری ماشینی نویز داده ها را نیز مدل کند. به طور شهودی، Overfitting زمانی اتفاق میافتد که مدل یا الگوریتم به خوبی با دادهها مطابقت داشته باشد. به طور خاص، اگر مدل یا الگوریتم بایاس کم اما واریانس بالا را نشان دهد، Overfitting اتفاق میافتد. Overfitting اغلب نتیجه یک مدل بیش از حد پیچیده است و می توان با آزمایش چندین مدل و استفاده از Validation یا Cross-Validation برای مقایسه دقت تخمین آنها در داده های آزمایشی از آن جلوگیری کرد. Underfitting نیز زمانی اتفاق می افتد که یک مدل آماری یا الگوریتم یادگیری ماشینی نتواند داده ها را به درستی مدل کند. به طور شهودی، عدم تناسب زمانی اتفاق میافتد که مدل یا الگوریتم به اندازه کافی با دادهها تناسب نداشته باشد. به طور خاص، اگر مدل یا الگوریتم واریانس کم اما بایاس زیاد را نشان دهد، Underfitting رخ میدهد. Underfitting اغلب نتیجه یک مدل بسیار ساده است.
سیستم توصیهگر سیستمی است که بسیاری از پلتفرمهای آنلاین از آن برای برای ایجاد توصیه هایی برای کاربران از منابع موجود در اپلیکیشن یا وب سایت خود استفاده می کنند. در واقع به شما کمک می کنند اولویت ها یا رتبه بندی هایی را که کاربران احتمالاً به یک محصول می دهند را پیش بینی کنید. به عنوان مثال، تصور کنید که ما یک پلتفرم پخش فیلم، شبیه به Netflix یا Amazon Prime داریم. اگر کاربری قبلا فیلم هایی از ژانرهای اکشن و ترسناک را تماشا کرده و دوست داشته باشد، به این معنی است که کاربر تماشای فیلم های این ژانرها را دوست دارد. در این صورت بهتر است چنین فیلم هایی را به این کاربر خاص توصیه کنید. این توصیه ها همچنین می تواند بر اساس آنچه کاربران با سلیقه مشابه تماشا می کنند ایجاد شود.

رگرسیون خطی به درک رابطه خطی بین متغیرهای وابسته و مستقل کمک می کند. رگرسیون خطی یک الگوریتم یادگیری نظارت شده(Supervised Learning Algorithm) است که به یافتن رابطه خطی بین دو متغیر کمک می کند. یکی پیش بینی کننده یا متغیر مستقل و دیگری پاسخ یا متغیر وابسته. در رگرسیون خطی، ما سعی می کنیم بفهمیم که چگونه متغیر وابسته نسبت به متغیر مستقل تغییر می کند. اگر فقط یک متغیر مستقل وجود داشته باشد، آن را رگرسیون خطی ساده و اگر بیش از یک متغیر مستقل وجود داشته باشد، به آن رگرسیون خطی چندگانه می گویند.

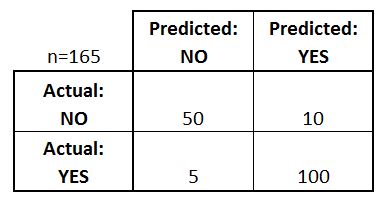
ماتریس درهم ریختگی جدولی است که برای تخمین عملکرد یک مدل استفاده می شود. مقادیر واقعی و مقادیر پیش بینی شده را در یک ماتریس 2×2 جدول بندی می کند. در مثال زیر ماتریس درهم ریختگی یک طبقهبند باینری را ملاحظه می کنید. در این مثال دو کلاس قابل پیش بینی وجود دارد: "بله" و "خیر". مثلاً اگر ما وجود یک بیماری را پیشبینی میکردیم، «بله» به این معنی است که آنها این بیماری را دارند و «نه» به این معنی است که آنها بیماری را ندارند. طبقه بندی کننده در مجموع 165 پیش بینی انجام داده است (به عنوان مثال، 165 بیمار برای وجود آن بیماری مورد آزمایش قرار گرفتند). از این 165 مورد، طبقه بندی کننده 110 بار "بله" و 55 بار "نه" را پیش بینی کرده است. فرض می کنیم که در واقعیت، 105 بیمار به این بیماری مبتلا هستند و 60 بیمار این بیماری را ندارند. اکنون بیایید ابتدایی ترین اصطلاحات را تعریف کنیم که اعداد کامل هستند (نه نرخ): موارد مثبت واقعی (TP): اینها مواردی هستند که در آنها پیش بینی کردیم بله (آنها این بیماری را دارند) و آنها این بیماری را دارند. منفی های واقعی (TN): ما پیش بینی کردیم نه، و آنها این بیماری را ندارند. موارد مثبت کاذب (FP): ما پیش بینی کردیم بله، اما آنها در واقع این بیماری را ندارند. منفی های کاذب (FN): ما پیش بینی نکردیم که خیر، اما آنها در واقع این بیماری را دارند.
کاهش ابعاد فرآیند تبدیل یک مجموعه داده با تعداد ابعاد (فیلد) بالا به مجموعه داده با تعداد ابعاد کمتر است. این کار با حذف چند فیلد یا ستون از مجموعه داده انجام می شود. با این حال، این کار به طور تصادفی انجام نمی شود. در این فرآیند، ابعاد یا فیلدها تنها پس از اطمینان از اینکه اطلاعات باقی مانده همچنان برای توصیف مختصر اطلاعات مشابه کافی است، حذف می شوند.

هرس درخت تصمیم فرآیند حذف بخش هایی از درخت است که ضروری نیستند یا زائد هستند. هرس منجر به درخت تصمیم گیری کوچکتر می شود که عملکرد بهتری دارد و دقت و سرعت بالاتری می دهد.

در الگوریتم درخت تصمیم، آنتروپی معیار ناخالصی یا تصادفی بودن است. آنتروپی یک مجموعه داده مشخص به ما می گوید که مقادیر مجموعه داده چقدر خالص یا ناخالص هستند. به زبان ساده، واریانس مجموعه داده را به ما می گوید. به عنوان مثال، فرض کنید جعبه ای با 10 تیله آبی به ما داده می شود. پس، آنتروپی جعبه 0 است زیرا دارای تیله های هم رنگ است، یعنی هیچ ناخالصی وجود ندارد. اگر یک تیله از جعبه بیرون بکشیم احتمال آبی بودن آن 1.0 خواهد بود.حال اگر 4 عدد از تیله های آبی را با 4 تیله قرمز در جعبه جایگزین کنیم، آنتروپی برای تیله های آبی به 0.4 افزایش می یابد.

هنگام ساختن یک درخت تصمیم، در هر مرحله باید یک گره ایجاد کنیم که تصمیم میگیرد از کدام ویژگی برای تقسیم دادهها استفاده کنیم، به عنوان مثال، کدام ویژگی (Feature) بهتر دادههای ما را جدا می کند تا بتوانیم به پیشبینی درستی برسیم. این تصمیم با استفاده از بهره اطلاعاتی(Information Gain) گرفته می شود. بهره اطلاعاتی مشخص میکند با انتخاب یک ویژگی خاص آنتروپی چقدر کاهش می یابد. آن ویژگی ای که بالاترین بهره اطلاعاتی را ایجاد میکند، برای تقسیم داده ها انتخاب میشود.

مجموعه داده را به k قسمت مساوی تقسیم می کنیم. پس از این کار k بار کار آموزش و تست را تکرار میکنیم به این صورت که در هر تکرار ، یکی از k قسمت برای تست و k − 1 قسمت باقیمانده برای آموزش استفاده می شود. در نهایت میبینیم که از تمام قسمت های داده برای آموزش و تست استفاده شده است. این نوع اعتبار سنجی به کاهش Overfitting منجر می شود.

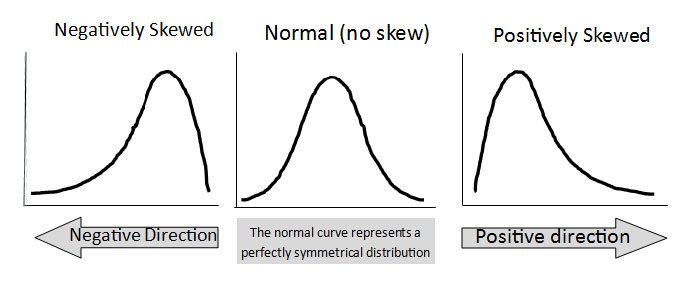
توزیع داده یک ابزار بصری برای تجزیه و تحلیل نحوه پخش یا توزیع داده ها است. داده ها را می توان به روش های مختلف توزیع کرد. برای مثال، میتواند به سمت چپ یا راست متمایل باشد، یا اینکه به هم ریخته باشد. داده ها همچنین ممکن است حول یک مقدار مرکزی، یعنی میانگین، میانه و غیره توزیع شوند. این نوع توزیع هیچ سوگیری به چپ یا راست ندارد و به شکل یک منحنی زنگی شکل است. در این نوع توزیع، میانگین آن برابر با میانه است. به این نوع توزیع، توزیع نرمال می گویند.
یادگیری عمیق نوعی یادگیری ماشین است که در آن از شبکه های عصبی برای تقلید از ساختار مغز انسان استفاده می شود و درست مانند نحوه یادگیری مغز از اطلاعات، ماشین هایی ساخته شده اند تا از اطلاعاتی که در اختیار آنها قرار می گیرد یاد بگیرند. Deep Learning یک نسخه پیشرفته از شبکه های عصبی برای یادگیری ماشین ها از داده ها است. در Deep Learning، شبکههای عصبی لایههای پنهان(Hidden Layers) زیادی را تشکیل میدهند (به همین دلیل به آن یادگیری عمیق میگویند) که به یکدیگر متصل هستند و خروجی لایه قبلی ورودی لایه فعلی است.

سوالی هست که اینجا نمیبینیش و از نظر تو مهمه؟ خودت سوالی داری که دنبال جوابشی؟ جواب بهتری واسه یکی از سوالای بالا داری؟ پس واسمون بفرست.
پایتون چیست؟
مزایای پایتون چیست؟
زبان نوع پویا (Dynamically-Typ...
زبان تفسیر شده (Interpreted) چ...
برو به همه سوالات
